

07/25/2024
Contributors: Christopher Ly, Humberto Talavera, Arjun Arun, Bob Hardgrove
Looking in the Rear View Mirror
Most healthcare data sources are not available in real time. A 30 to 90-day lag for claims processing remains the industry standard. This delay in healthcare data availability drives many healthcare data organizations to concentrate their efforts on optimizing their batch ETL (Extract, Transform, Load) technologies. Common ETL tools used in the industry include:
- Informatica
- Talend
- Fivetran
- Oracle Data Integrator
At Astrana Health, we recognize that real-time insights are the future, even as we currently rely heavily on batch processing. One area where we leverage real-time streaming technologies is in ingesting ADT (Admission, Discharge, Transfer) data to support Astrana Health’s Inpatient Management workflows.
When one of our patients visits the hospital, timely communication is crucial. How quickly can our hospitalists be informed that our patient is in the ER? What about our post-discharge team, which coordinates care between the hospital and the patient’s primary care physician? In all cases, the faster the information is relayed, the better. Given this need for speed, the ingestion and use of ADT data are particularly unsuited for batch processing.
Streaming Healthcare Data
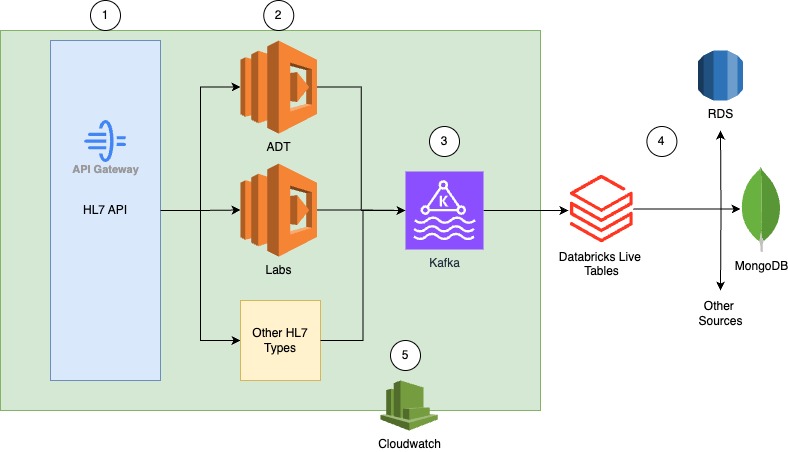
The main technologies used in our event-driven streaming system are AWS (Amazon Web Services) Lambdas, Apache Kafka and Databricks Delta Live Tables (DLT). This architecture allows us to elastically scale based on volume of data and stream the data into as many software applications as needed.
Key Components of Each Technology
AWS Lambda is a serverless compute service provided by AWS that allows us to run code without provisioning or managing servers. It automatically scales and manages the infrastructure needed to run our code in response to triggers, such as data changes or incoming requests. For instance, if we experience an overnight spike in volume from 10,000 ADT messages per day to 100,000 ADT messages per day, Lambda will automatically allocate the necessary compute resources to handle the increased load and then scale down once the demand decreases.
Apache Kafka is a high-performance, distributed streaming platform that allows us to publish, subscribe to, store, and process streams of records in real time. It acts as a central nervous system for our data infrastructure. Kafka comes with features like topic-based data labeling. For instance, consider a use case where a patient sends a text message that we want to combine with an ADT diagnosis in a consolidated alert to a Care Manager in real time. With Kafka, we can label both the patient_text and the ADT diagnosis, then route the information appropriately for seamless integration and timely alerts.
Databricks Delta Live Tables are a feature of Databricks that enable real-time data ingestion through a structured streaming interface for continuously updating tables. This technology allows us to query and update tabular data in real-time, serving as the final destination for our real-time data streams.
Security First
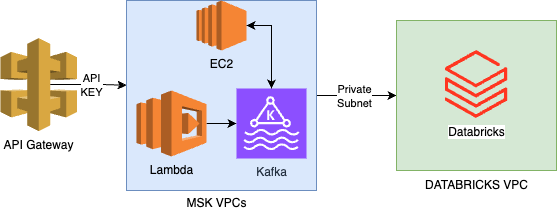
In any healthcare business, security is a top concern. Therefore, our Databricks environment and Kafka clusters are each hosted on their own VPCs and communicate with each other using a private subnet via an AWS Peering connection. The API gateway can interact with the MSK VPC only through a Lambda function, which requires proper API key access provided by Astrana Health. This ensures that only authorized entities, with the correct API key distributed by us, can interact with the system.
Apache Kafka & Databricks
One of the key achievements of this architecture is enabling our MSK Clusters (Kafka) to communicate seamlessly with our existing Databricks environment. In addition to the networking security measures previously described, we also had to configure specific policies to allow Databricks to access and utilize certain AWS services. For security reasons, we won’t share our exact policy, but you can view an example below:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kafka-cluster:Connect",
"kafka-cluster:AlterCluster",
"kafka-cluster:DescribeCluster"
],
"Resource": [
"arn:aws:kafka:us-east-1:0123456789012:cluster/MyTestCluster/abcd1234-0123-abcd-5678-1234abcd-1"
]
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:*Topic*",
"kafka-cluster:WriteData",
"kafka-cluster:ReadData"
],
"Resource": [
"arn:aws:kafka:us-east-1:0123456789012:topic/MyTestCluster/*"
]
},
{
"Effect": "Allow",
"Action": [
"kafka-cluster:AlterGroup",
"kafka-cluster:DescribeGroup"
],
"Resource": [
"arn:aws:kafka:us-east-1:0123456789012:group/MyTestCluster/*"
]
}
]
}
To enable Databricks to utilize this policy, we configured the Kafka consumer with specific parameters to successfully access the MSK Cluster via AWS IAM. The key configuration parameters are:
"kafka.sasl.mechanism": "AWS_MSK_IAM",
"kafka.sasl.jaas.config":
"shadedmskiam.software.amazon.msk.auth.iam.IAMLoginModule required;",
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.client.callback.handler.class":
"shadedmskiam.software.amazon.msk.auth.iam.IAMClientCallbackHandler"
The Kafka consumer we created is now capable of actively listening to a vendor-specific topic and is ready to read any new messages as they come in. This real-time data ingestion ensures that our systems are always up-to-date and responsive to the latest information.
HL7 Parser
Now that we have successfully ingested data into our Databricks environment, we needed a method to transform the HL7 messages into a format that meets our business needs. We decided to use an established HL7 Python package, as it allows us to write code that closely matches the structure of HL7 messages. Below is a code snippet of our parser and an example of how vendors define these variables:
data = {
'facility_name': msg_parsed.segments('MSH')[0][3][0],#MSH.3 - Sending Application
'patient_name': str(msg_parsed['PID'][0][5][0][1])+str(msg_parsed['PID'][0][5][0][0]), #PID.5.1- Family name, PID.5.2 - Given Name
'patient_id': str(msg_parsed['PID'][0][3][0][0]),# PID.3 - ID
'patient_dob': msg_parsed.segments('PID')[0][7][0], #PID.7 - Date/Time Of Birth
}
With security and logic in place, we were now able to start ingesting data and stress-testing our new architecture. This ensured that our systems were robust and capable of handling the expected load, providing reliable and timely data processing for our healthcare operations.
Load Testing the Architecture
To test the robustness of the architecture, we sent multiple batches of 100,000 ADT messages to the API to measure the average time it takes for each message to reach the first table. Initially, we attempted to send these messages using as many threads as possible, without limiting the number of threads.
However, we discovered that opening too many threads actually slowed down the number of requests we could send per second. After fine-tuning the test, we successfully sent 100,000 ADT messages in approximately 30 minutes, with each message taking an average of 4 to 5 seconds to reach the first table from the time it was sent.
Please note that the bottleneck in these tests was the cluster sending the 100,000 ADT messages, rather than the architecture receiving and processing them. Therefore, we expect the system to perform even faster in production!
Summarized
- Scale Seamlessly: Kafka’s distributed architecture, AWS lambda functions, and Delta Live Tables allow us to elastically scale to meet growing data demands without compromising performance or requiring significant engineering resources.
- Integrate Anywhere: Currently, Databricks Delta Live Tables is the only client utilizing Kafka. However, we can build several other clients on top of the same data Kafka topics without disrupting the flow to other clients or applications (patient applications, provider applications, care management applications, utilization management applications, etc.).
- Ensure Data Security: All data flows within our private VPC and is encrypted when stored in Kafka. Only trusted clients can access the data from Kafka, and only specified users can utilize the API via OAuth Authentication.
- React Instantly: With Delta Live Tables and additional monitoring set up through AWS (Cloudwatch), we can monitor the data from start to finish, pinpoint the exact location of any errors, and address them in real time.
Thinking about working with us? We’d love to chat! Take a look at our open positions: here