

Investing in Technology to Speed Up the Quality Improvement Cycle
Mon 08 Jan 2024
Contributed by David Roberts, Kevin Buchan, Jr., and Yubin Park
The Healthcare Effectiveness Data and Information Set (HEDIS®) by NCQA plays a central role in many Value-Based Care (VBC) operations. HEDIS is a set of measure definitions that track healthcare processes, outcomes, and patient satisfaction. Improving these measures, or “closing care gaps,” is vital to providing high-value care and is often associated with financial incentives.
However, Improving HEDIS® is More Challenging Than It Seems.
It is hard for many reasons, but in this article, let’s focus on the administrative side challenges.
First, the HEDIS® logic definitions are not straightforward to implement. Healthcare data are inherently complex and messy; thus, to capture the true “quality,” the logic definitions must also identify the correct cohorts for the measurements and handle various exception cases.
Second, HEDIS® outputs often do not reflect the latest data. Most value-based care organizations calculate the HEDIS® outputs quarterly or monthly at best, stacking additional latency on top of the glacial claims adjudication process. Thus, the HEDIS® outputs show the results of one to two months (or many months) ago. Such outdated (and hence wrong) results are one of the primary sources of provider abrasion regarding many quality improvement initiatives.
Third, many new data sources are available to augment the HEDIS®-related insights, but the vendors are slow to adopt such. Traditionally, HEDIS® uses administrative data, i.e., claims, to calculate the outputs. However, the community is adopting more data sources, such as Electronic Health Records, additional evidence from community workers, and other SDOH data. Integrating these new data sources with the existing vendor outputs often becomes a roadblock to further innovation in the area.
Finally, vendor outputs are not transparent to provide actionable insights. In many HEDIS® improvement projects, it is critical to understand “why” a particular care gap is closed or open. If the care gap is closed, we need to be sure which claim qualified for the gap closure and which doctor was involved. If not, we must develop appropriate outreach strategies, e.g., scheduling an appointment or following up with a PCP. However, most HEDIS® vendors fail to provide that much granular information.
We at Astrana Health believe accurate, reliable, and timely updates of HEDIS® measures are prerequisites for providing high-quality patient care. Based on the technical challenges above, and as a leading VBC provider organization, we embarked on the journey of implementing our HEDIS® engine in 2022 by ourselves. Since then, we have received NCQA certifications for our HEDIS® engine and have been working hard to tackle the current HEDIS® challenges. We want to share one of our exciting new developments with this article.
The below diagram shows our current HEDIS® engine and data pipeline:
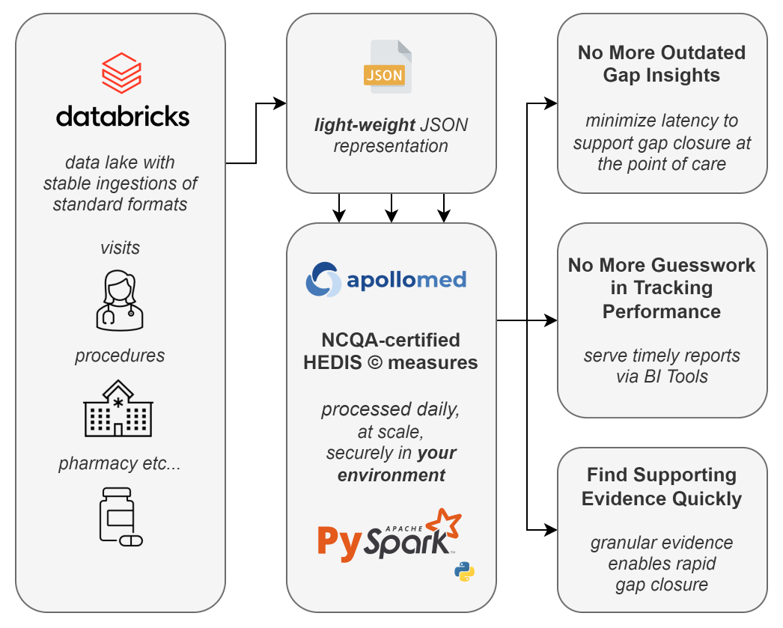
Let’s Build a Fast and Transparent HEDIS® Engine!
When implementing the HEDIS® logic in 2022, we decided to use Python, a general-purpose programming language. Having a Python-based HEDIS® engine gave us a lot of flexibility, such as running the engine on various platforms. At first, we ran the engine on a Ubuntu Virtual Machine (VM). It was already faster than any other vendors in the market and running fine. However, we wanted to push the envelope further. In 2023, we transitioned our quality engine and data to our Databricks Delta Lake. With the shift to Databricks, we achieved a 5x runtime savings over our previous approach. Our HEDIS® engine runs over a million members through 20+ measures for two measurement years in roughly 2.5 hours! Frankly, we are thrilled with the result. With this setup, we can:
- consolidate a complicated process into a single tool
- minimize runtime
- provide enhanced transparency to our stakeholders
- save money
Scaling is Trivial with Pyspark
Our first implementation on an Ubuntu VM extracted HEDIS® inputs as JSON documents from an on-prem SQL server. The VM was costly (running 24×7), with 16 CPUs to support Python pool-based parallelization.
With pyspark, we register a Spark User-Defined Function (UDF) and rely on the framework to manage parallelization. This modification yielded significant performance benefits and is more straightforward to read and communicate to teammates. With the ability to trivially scale clusters as necessary, our implementation can support the needs of a growing business. Moreover, with Databricks, you pay for what you need. We have reduced the compute cost by at least 1/2 in transitioning to Databricks Jobs clusters.
Parallel Processing Before…

Parallel Processing After…

Traceability Is Enabled by Default
As data practitioners, we are frequently queried by stakeholders to explain unexpected changes. While cumbersome, this task is critical to retaining users’ confidence and ensuring they trust our data. If we’ve performed our job well, changes to measures reflect variance in the underlying data distributions. Other times, we make mistakes. Either way, we are accountable to understand the source of a change.
A screenshotted measure. “Why did this change?! It was 52% last Thursday”

In the Databricks Delta Lake, the ability to revert datasets is a default. With a Delta Table, we can quickly inspect a previous version of a member’s record to debug an issue.

We have also enabled change data capture on aggregate tables (provider level, provider group level), which automatically tracks detail-level changes. This capability allows us to reproduce how a rate changes over time.

Reliable Pipelines with Standardized Formats
Our quality performance estimates are a key driver for developing a comprehensive patient data repository. Rather than learning of poorly controlled diabetes once a month via health plan reports, at ApolloMed, we ingest HL7 lab feeds daily and updates our HEDIS® outputs accordingly. In the long term, setting up reliable data pipelines using raw, standardized data sources will facilitate broader use cases, e.g., custom quality measures and machine learning models trained on comprehensive patient records using FHIR bundles from HIEs. As Micky Tripathi marches on and U.S. interoperability improves, we are cultivating the internal capacity to ingest raw data sources as they become available.
Enhanced Transparency
We coded the ApolloMed quality engine to provide the actionable details we’ve always wanted as consumers of quality reports. Which lab met the numerator for this measure? Why was this member excluded from a denominator? This transparency helps report consumers understand the measures they’re accountable to and facilitates gap closures.
Interested in learning more?
The Astrana Health quality engine has 20+ HEDIS Certified Measures is now available to be deployed in your Databricks or any Python-runnable environment. To learn more, please review our Databricks solution accelerator or reach out to da_sales@astranahealth.com for further details.
In this article, we shared our journey of building a more accurate, reliable, and timely HEDIS® engine to provide high-quality patient care. We thank everyone who was involved in this project. Let’s keep pushing the envelope of value-based care analytics!